
Proof of Concept – Migrating Notes RichText to Markdown – Part III
In this last post I’ll give you a walkthrough of this PoC. The full source code is available on GitHub (see end of the post).
The simplified code example
As I’ve described in my previous post I’m going to read all entries in a given view using the ReadViewEntries URL parameter. Read more about it in this cheat sheet (from 2002!). The call gives us basically one root element with a “viewentry” array. The array contains all documents, categories etc. as siblings. So it’s quite easy to get all documents.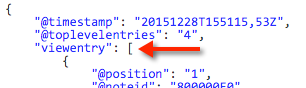
The next screenshot shows an example “viewentry”. It contains some metadata elements, like the position in the view, the Notes UNID or the column values (in the “entrydata” element).
When you look at this representation it’s obviously not the best one. Nowadays one would use the Domino Access Services or create a custom HTTP plugin. But that wouldn’t meet my preconditions.
With now knowing the structure of the view data we’ll first setup a model class that will later represent the gathered data. This screenshot shows you the properties I’ve set.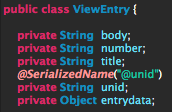
Here is an explanation of them:
- body: this property will later hold the HTML that needs to be converted to Markdown
- number: this will hold the value of the help_number column of the view
- title: this will hold the value of the help_title column of the view
- unid: as the name says - it’ll hold the UNID of the document. Please note that I’ve annotated it with @SerializedName. This is an annotation from Gson (I use Gson here to convert the JSON to model objects). It allows to work with JSON keys that contain special characters.
- entrydata: this is a raw object. As you’ve seen in the JSON above entrydata can contain several elements. I didn’t want to re-create them in the model.
The process is now pretty straightforward. The result of the ReadViewEntries call gets passed to Gson’s JsonParser which then creates the root element. I’m grabbing from there the viewentry element and Gson creates the ViewEntry array.
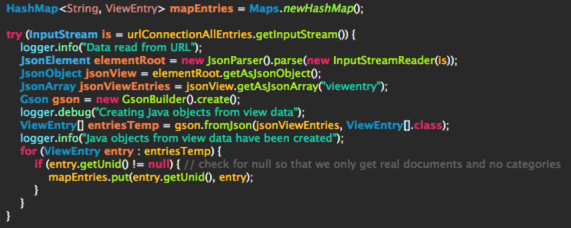
I’m skipping here the iteration, you can see that in the full code. What I want to point out is how Gson handles stuff. The original JSON contains an entrydata key which then contains an array and more subsequent elements. Gson converts that automatically to a LinkedTreeMap (as you can see below). As I’ve defined the entrydata variable as type Object I can now easily cast the result and add more data to the model objects.
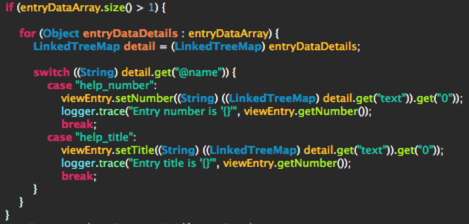
After getting the value of the RichText field via the OpenField call it’s now only about creating a new Remark object and calling it’s convertFragment method. I’m using Guava for cleaning up the titles from the view so that I’ve usable file names.
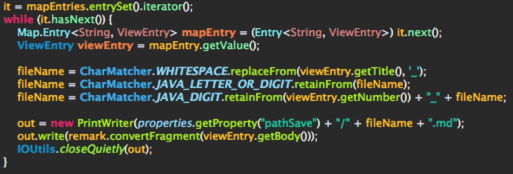
That’s all. You can find the full source code here.
The caveats
Are there caveats? Oh yes!
We’re converting from a format that does a lot of nice (and weird) stuff like tabbed tables to a pretty “simple” format. Markdown doesn’t do this. There is also no interpretation of bold, italic and underlined text at the same time. Or colored font. Or different font sizes. Or inline images.
So you’ve to do manual cleanup. Define exactly what you want and do some pre-work. Like modifying the gathered HTML with Jsoup (bundled with Remark) before you convert it.
The result
First of all: the goal has been achieved - a Proof of Concept for converting Notes RichText to Markdown. And now…?
There are lots of use cases. If you go for example with GitBook as documentation system you can directly create the structure of a GitBook summary.md during the migration process (plus file and folder structure). And from there on auto-create your documentation when certain criteria, like a version tagged master branch in git, are met by using node on your build server.
Or re-use the Markdown in your XPages web application. Or…or…or…
Have fun!
